Udacity Data Scientist Nanodegree: Project 1
As part of my Udacity Data Scientist Nanodegree program, my first project involved using CRISP-DM analysis and applying them to a real set of data to answer some questions about our findings. Step 1 of the process is all about understanding the business or the domain. This was a key point for me. I wanted to analyze data on a subject I already knew about, instead of trying to go down a path where I have little or no experience. Given the timelines and the fact I have a day job, it was easy to go with a business domain I already know.
For example, as interesting as COVID-19 vaccine data sounds, in light of the recent global pandemic, I was not about to try and learn about vaccine trials and microbiology, neither of which are in my wheelhouse. However, as I looked over the available data on Kaggle.com the subject of New York City real estate drew my attention. Not only is this a subject which I have recent experience analyzing but also one which I have some personal experience as well. I lived in several apartments in Manhattan early in my career while working on Wall Street, I proposed to my wife in Times Square while on a horse and buggy tour. How much more New York does it get, right? And since then, we have bought and sold a few houses ourselves once we left the hustle and bustle of the city to raise a family.
 Source: GETTY image from forbes.com: https://www.forbes.com/sites/forbes-global-properties/2021/08/26/how-will-inflation-impact-new-york-real-estate-experts-share-5-factors-to-consider/?sh=6b551f324efa
Source: GETTY image from forbes.com: https://www.forbes.com/sites/forbes-global-properties/2021/08/26/how-will-inflation-impact-new-york-real-estate-experts-share-5-factors-to-consider/?sh=6b551f324efa
The NYC Real Estate Data I found on Kaggle.com involves sales of properties during a one-year period across the five boroughs of New York City. The source for this data can be found here: https://www.kaggle.com/new-york-city/nyc-property-sales. Part of this exercise is to construct three questions which I will try to answer as a result of my analysis. However, what I have found so far with data mining is that many times the questions do not completely form themselves until after you started the process. But for the sake of argument, I will note the 3 initial questions I set out to answer and then see how much they vary over during the data mining process.
I will initially attempt to answer the following 3 questions:
- Does Manhattan or the borough in general have any effect in predicting the sales price of a property?
- Are older buildings selling better than newer buildings based on location, given that most older buildings are rent controlled in New York?
- Is there a correlation in sales with time of year and square footage for any particular borough? For example, are Manhattan apartments selling faster in the winter or are lofts in Brooklyn in higher demand during the summer months?
“The world is one big data problem.” – by Andrew McAfee, co-director of the MIT Initiative
As per the CRISP-DM or Cross-Industry Standard Process for Data Mining, I followed these 6 steps:
Step 1: Business Understanding
I needed to make sure I knew enough about real estate and the factors that may affect sales. Also, I needed a general understanding of the boroughs or sections that make up the city of New York as well as some of the neighborhoods within those boroughs. Typically, people not familiar with New York City know more about the borough of Manhattan from movies and TV but have very little knowledge of the surrounding boroughs. Perhaps they know more about Brooklyn more recently, but probably have very little awareness of boroughs like the Bronx, Queens, or Staten Island.
 Source: Battery Park City: Suburban Living in the Heart of New York City - Christie’s International Real Estate https://www.christiesrealestate.com/blog/battery-park-city-suburban-living-in-the-heart-of-new-york-city/
Source: Battery Park City: Suburban Living in the Heart of New York City - Christie’s International Real Estate https://www.christiesrealestate.com/blog/battery-park-city-suburban-living-in-the-heart-of-new-york-city/
The first time my sister visited me in lower Manhattan she was surprised to see how “nice” Battery Park City appeared. She noted that it was nothing like “the mean streets of New York” she had seen in the movies. Her views changed when we took the subway up to 42nd street and saw the sights there. “This is more like what I thought New York City would look like!” she said.
Source: Business Insider https://www.businessinsider.com/facts-about-times-square-2017-3
Step 2: Data Understanding and Step 3: Data Preparation
In order to understand the dataset, I was analyzing I needed a bird’s eye view of the data or a general overview of what I was looking at without looking at every single row and column on the file. The Python Pandas package allowed me to get this high-level overview. I loaded the CSV file I got from Kaggle into something Pandas calls a “DataFrame” and ran a describe function to get a high-level overview of the data. I also generated some histograms to see the level of data wrangling and clean up I might have to do across the various columns of the file. This including possibly dropping a column that might be completely empty or a row that had nothing in it. As well as imputing missing data, which is like filling in the missing blanks where it makes logical sense. It is important to do some “sanity checks” here as well. You want to make sure you have data that “makes sense”, e.g., not an empty file, not a file with too little data, not a bunch of empty columns, or data that is inconsistent or not what you thought you had. Imagine if somehow the file I downloaded was Boston suburbs real estate data or stock prices for an obscure company. We want to level set here and start on the right foot.
Now Some Python Code to Understand Our Data
# First initialize my environment with things I will need to run my code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import ALookAtTheData as t
from IPython import display
%matplotlib inline
# Load the CSV file into a Pandas DataFrame where I can run some functions to tell me more about the data I was looking at
df = pd.read_csv('./nyc-rolling-sales.csv')
# Look at the first few lines to make sure the data seems reasonable
df.head()
But Enough About Code
Rather than dive into the technical details let’s discuss what was involved in the analysis. Notice that we combined Step 2: Data Understanding and Step 3: Data Preparation. In data science they say this is about 80% of the work: wrangling the data. I found the two steps to be cyclical. The more I needed to understand the data, the more I had to clean it up and prepare it to analyze it.
We did things like map borough numbers to actual borough names so we could plot some bar graphs for our analysis.
Also, a valuable tool was our heat map which gave us numeric correlations across our data. This way we could see what numbers really correlated to sales price and what were insignificant. Surprisingly time of year or season had very little or close to 0 correlation which helped with question 3 in our evaluation. We later further proved this by adding and removing from the model input and seeing no variance in the result.
 Source: NY Times New York City Doesn’t Have to Suffer This Summer https://www.nytimes.com/2020/05/25/opinion/new-york-summer-coronavirus.html
Source: NY Times New York City Doesn’t Have to Suffer This Summer https://www.nytimes.com/2020/05/25/opinion/new-york-summer-coronavirus.html
No, not a heatmap like a hot summer in the Astoria Pool in Queens, NY. The type of heatmap graphic used by data scientist to see numbers that are color coded to show high or low correlations.
 Source: https://indianaiproduction.com/seaborn-heatmap/
Source: https://indianaiproduction.com/seaborn-heatmap/
Step 4: Modeling
For our modeling step, I decided on taking my numeric inputs from my analysis: things like borough, year the property was built, and the tax category of the property at sale time to do a linear regression to sale price. Meaning, whittle down the data to the factors that most affect sale price predictability. Linear regression is a machine learning model that employs a best linear fit, which is fancy talk for take a bunch of data points with an X and Y axis, now try to draw a straight line that most closely lays over those points. In the diagram below you have two examples of a linear fit or red line that fits along all those points. Notice the thing they are calling r^2 or R-Squared. This value is important in linear modeling because it tells you how well your line fits and ultimately how well your model is performing. Notice the second diagram fits better along those points and thus has a higher R-square (called R-Sq on the legend to the right of the plot).
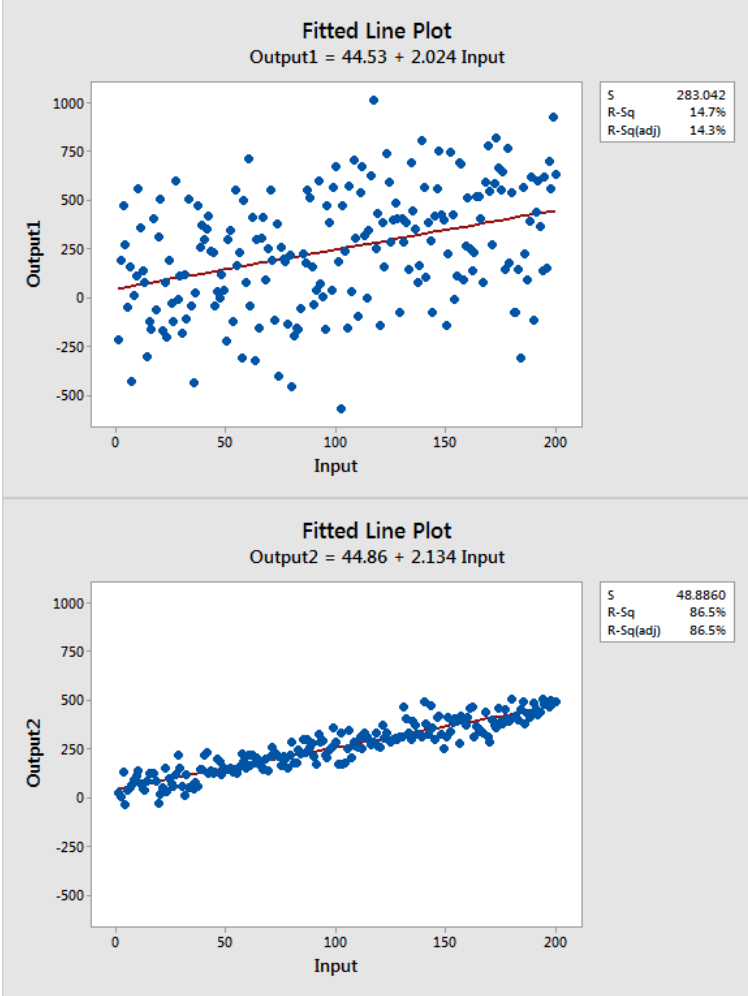 Source: miro.medium.com at https://medium.com/@erika.dauria/looking-at-r-squared-721252709098
Source: miro.medium.com at https://medium.com/@erika.dauria/looking-at-r-squared-721252709098
Along the way I realized that inputs like Zip Code, Block, and Lot were simply redundant in terms of location which I was interested in a by Borough analysis in the first place. So those redundant location factors were dropped from the model. Also, factors that I found had no correlation to the sale price or skewed the results were also dropped as inputs. Factors like total units, gross square feet, or land square feet either skewed our R-square result into a negative number, meaning invalidated the model, or had no effect in moving the result.
Step 5: Evaluation – A summary of our Results
Some results were as expected, while others were a little surprising. Below are the results:
 Source: http://www.manhattanrealestate.com/
Source: http://www.manhattanrealestate.com/
| # | Question | Results |
|---|---|---|
| 1 | Does Manhattan or the borough in general have any effect in predicting the sales price of a property? | YES it impacts the price by a 35% difference in r-square value. Although Queens and Brooklyn have more sales (more than 50% of the sales together), Manhattan has the higher priced sales (over 50%). |
| 2 | Are older buildings selling better than newer buildings based on location? | NO not really, the impact is only about a 4% difference in r-square value. This was a little surprising given the older buildings are typically rent-controlled. |
Regarding question 2, if we remove YEAR BUILT from our model the r-square does drop from 0.023 down to 0.022. This is how we derived our answer.
The results for question 2 were surprising enough to make us pause and re-evaluate our data. Perhaps we were looking at newer buildings that went up post-WWII. But a second look at the counts by YEAR BUILT confirmed this was not the case. We were in fact looking at a lot of buildings that went up early 1900s.
| # | Question | Results |
|---|---|---|
| 3 | Is there a correlation in sales with time of year and square footage for any particular borough? For example, are Manhattan apartments selling faster in the winter or are lofts in Brooklyn in higher demand during the summer months? | NO none at all in fact. Neither SALE DATE nor SALE SEASON NUMBER made any difference in our r-square value model. And we have already ruled out square footage as only skewing results so no correlation here either. |
Step 6: Deployment
This step is more about the results you are reading here in my blog as well as the Jupyter Notebook with the actual code and detailed analysis. This can be found here on my GitHub project repository: https://github.com/hmelendez001/Project1-Udacity-Data-Scientist
In conclusion, this has been a rewarding experience. I found by writing this blog in a manner that was easy for anyone to understand it gave me a deeper understanding of what I had to do in my analysis. Some false starts or bad assumptions were corrected, some lessons learned, and some results were derived that were not expected. And most importantly, it has really gotten me excited about data science. I have to admit, learning the basic concepts can be monotonous and initially challenging but taking on this project has revitalized my interest in the subject, and I am excited about our next projects in the program.
Now I just want to eat a hot dog from Gray’s Papaya off 72nd and Broadway in the Upper West Side of Manhattan, greatest hot dog on earth. :)
 Source: nymag.com The best hot dogs on the Upper West Side at https://nymag.com/listings/restaurant/grays-papaya/
Source: nymag.com The best hot dogs on the Upper West Side at https://nymag.com/listings/restaurant/grays-papaya/